Resources
That's Fresh! Newsletter
Read a selection of our past issues.
FROM THE AI WORLD
This week's recommendation is a review work published by the van der Schaar Lab. It discusses the growing interest in the machine learning (ML) community for synthetic data, which extends beyond its initial use for privacy preservation.
The paper discusses different applications of synthetic data as a means to tailor datasets to individual needs, offering potential benefits like fairness, data augmentation, and simulation.
The work also discusses the fundamental challenges before it can be widely adopted, particularly in quantifying the trust in findings derived from synthetic data. These include developing better metrics for quality and privacy, understanding the suitability of different generative models, handling outliers and underrepresented groups, comprehending the influence of synthetic data on downstream tasks, establishing verification protocols, and deciding on publishing and access methodologies for synthetic data.
The paper advocates for a paradigm shift in ML towards using customizable, realistic synthetic data. Still, it emphasizes the need for urgent solutions to ensure the trustworthiness and broader application of synthetic data.
Reading this review, we saw ourselves as well, as it touches upon many of the points we had to deal with as a startup operating in the domain!

Navigating the synthetic data sea
This technology is not only about privacy. Its potential reaches fair data, simulation, data augmentation and more. Want to know more?
CLEARBOX AI
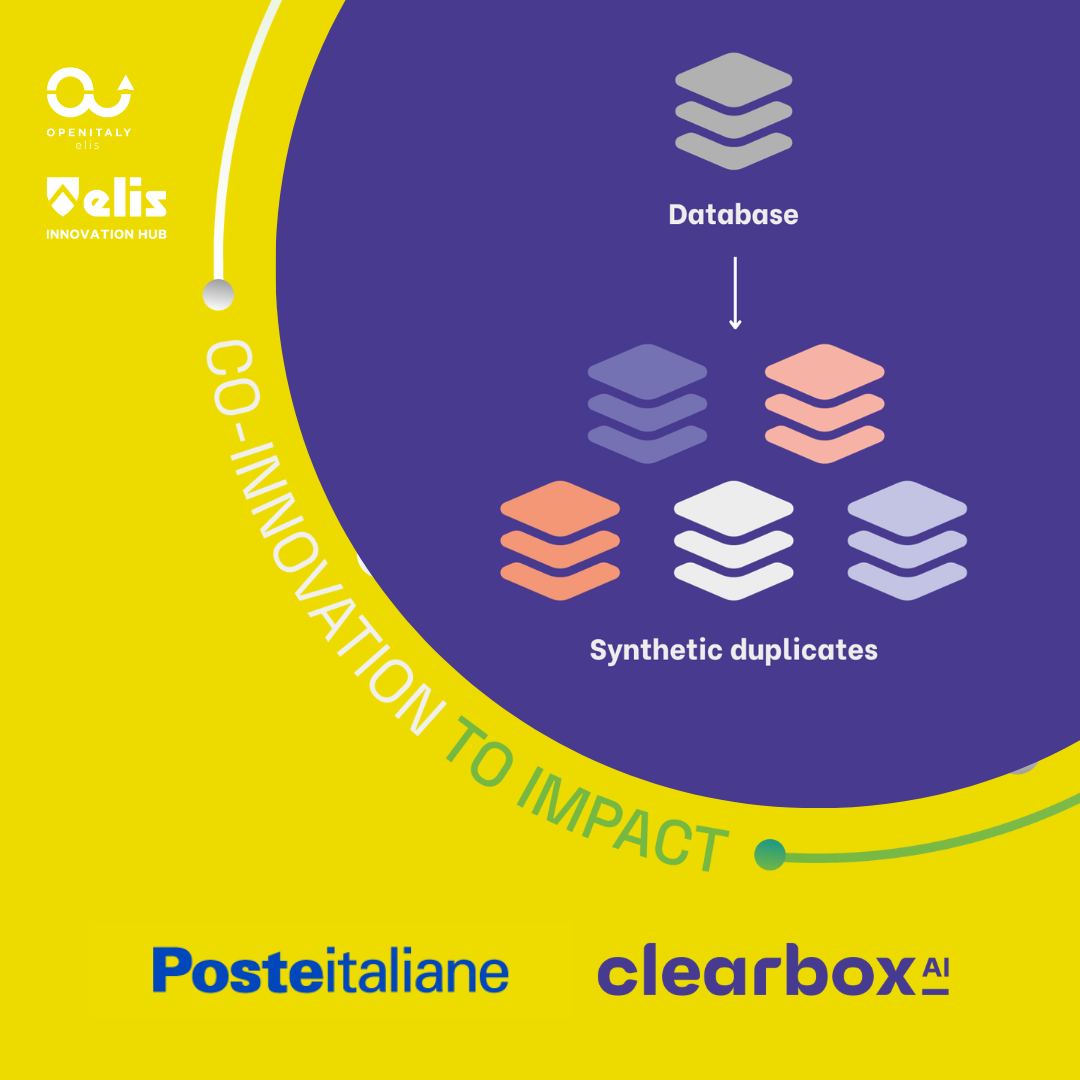
New project with Poste Italiane
We are proud to start this project with Poste Italiane in the context of OPEN ITALY program. The initiative aims to test the new Synthetic Data paradigm.
BLOG POST

Why synthetic data?
Speaking of AI generated data, many times we are asked how this kind of data can be used in practice and how it improves real data. We answered in this video.
WEEKLY MEME
Your pals may also like...
