Services
Data-Centric AI for your business
From synthetic data to AI consultancy, our services help you prepare, scale, and value your data.
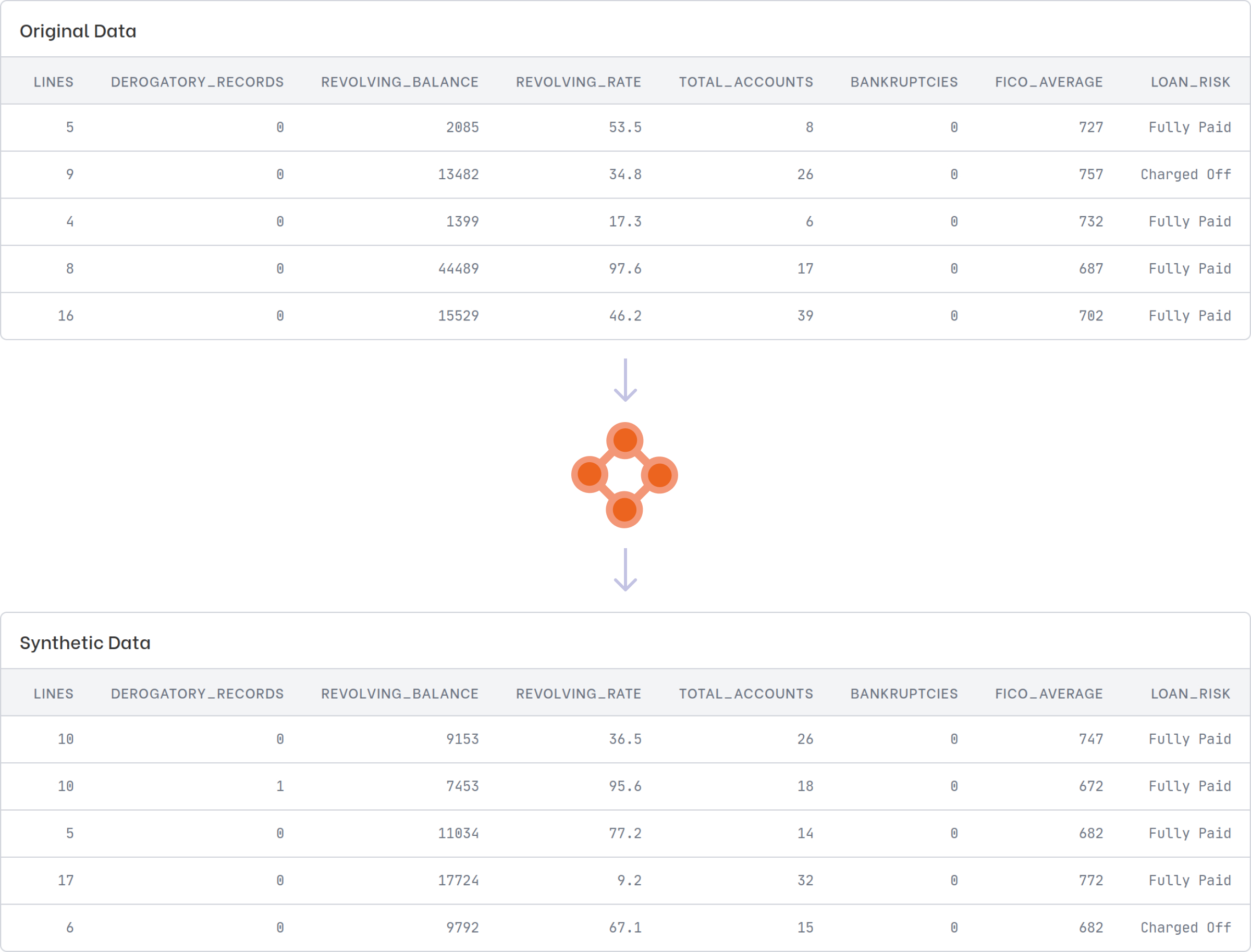
With Clearbox AI Enterprise Solution, you will be able to enjoy the benefits of high-quality structured synthetic data generated by our proprietary Data Engine.
Our Enterprise Solution is a fully dockerized solution. You can install it on-prem or on the cloud. We designed it to be a turnkey solution for your company's needs. You can generate synthetic data from a structured data source, such as data coming from a relational database or a data warehouse.
Architecture
Clearbox SDK
Effortlessly integrate synthetic data into your processes with our powerful Python SDK.

Web-based frontend
Easily interact with the Enterprise Solution and its output through a built-in frontend.
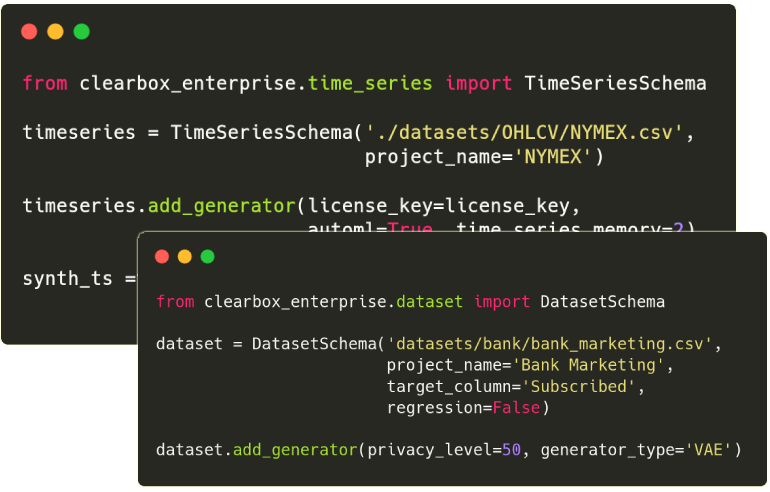
SDK Quickstart
from clearbox_enterprise.dataset import DatasetSchema
dataset = DatasetSchema('bank_marketing.csv', target_column='Subscribed', regression=False)
Data Cloning
dataset.add_generator(privacy_level=50, generator_type='VAE')
Data Augmentation
from clearbox_enterprise.data_augmentation import augment_data
augmented_dataset = augment_data(dataset,'generator_name',n_iter=20)
Time Series
from clearbox_enterprise.time_series import TimeSeriesSchema
ts_data = TimeSeriesSchema('nymex.csv', project_name='NYMEX')
ts_data.add_generator(automl=True, time_series_memory=2)
synth_ts = ts_data.generate_time_series(n_time_steps=1000, fidelity=100)
Data Connectors
from clearbox_enterprise.data_connector import BigQueryConnector
connector = BigQueryConnector("credentials.json", "project-id")
dataset = connector.table_to_dataframe(dataset_id='data_id', table_id='table-id')