
What is data preprocessing?
Data preprocessing lays the cornerstone for successful machine learning endeavours, serving as the crucial initial step in refining raw data into actionable insights. As we described in one of our previous blog posts, pre-processing data is the bedrock of model development. Preprocessing techniques are indispensable for enhancing data quality, reducing noise, and ensuring compatibility with machine learning algorithms.
From handling missing values and scaling features to encoding categorical variables and extracting meaningful features, the preprocessing phase holds the key to unlocking the full potential of machine learning models. In this era of data-driven decision-making, mastering the data preprocessing is paramount for driving innovation, uncovering hidden patterns, and achieving optimal model performance.
Clearbox AI’s Data Preprocessor
Starting point: Pandas, Scikit-learn, Polars
At Clearbox AI, we had already developed a simple Preprocessor tool to facilitate tabular data preparation, typically used in machine learning workflows, employing the well-known and widespread Python libraries pandas and scikit-learn.
We wanted to boost its performance and make this Preprocessor more scalable with the number of rows of the dataset fed to the tool. So, we decided to completely renew the existing Preprocessor into the Preprocessor 2.0 and expand its capabilities by rewriting it with the library Polars.
Polars is a dataset-handling library written in Rust and available in Python, which gives your code C/C++ speed performance. It uses Apache Arrow, a columnar data format, to process the queries in a vectorized manner to optimise CPU usage. It can also divide the workload among the available CPU cores without additional configuration and allows for out-of-core data-handling. In fact, the streaming API allows to process the results without requiring all the data to be in memory at the same time, with the possibility to handle much larger datasets than the available RAM. It supports all the most common data types and storage layers (cloud & databases).
What are the benefits?
The new Preprocessor v2.0 can ingest a large amount of data, making its predecessor eat the dust, opening to the possibility of scaling its employment to dataset with hundreds of millions and even billions of rows. Besides being blazing fast, the novelties we introduced are the boolean and temporal data types handling and the processing and extraction of relevant features of time-series. The usage of this module is straightforward; exploiting its default settings the user can quickly obtain consistent results. But if needed, it also allows for a high degree of customization in the process, to let the user maintain full control over every aspect of the process.
Data preprocessor features
Let's take a closer look at some of its key functionalities:
Flexible input handling
Whether your data resides in a pandas DataFrame or a Polars LazyFrame, the Preprocessor class seamlessly accommodates both, ensuring compatibility across different data structures.
Dynamic feature selection
Leveraging advanced algorithms, the Preprocessor class intelligently identifies the most informative features while discarding redundant or irrelevant ones. By setting a discarding threshold, users can fine-tune the selection process to suit their specific requirements.
Efficient missing value imputation
Missing data is a common obstacle in real-world datasets. The Preprocessor class offers robust strategies for handling missing values, depending on the feature type, including interpolation, most frequent value and customizable fill-in methods such as mean, forward/backward filling, and more.
Scalable scaling options
Scaling numerical features is crucial for maintaining consistency and improving model performance. With the Preprocessor class, users have the flexibility to choose between normalisation and standardisation techniques, ensuring optimal data scaling tailored to their needs.
Streamlined categorical encoding
The Preprocessor class simplifies the encoding process with built-in support for one-hot encoding and efficient handling of categorical data, minimising the risk of information loss and enhancing model interpretability.
Time-series feature extraction
Time-series data requires specialised treatment to extract meaningful insights. The Preprocessor class integrates seamlessly with the tsfresh library, enabling users to extract relevant time-series features effortlessly, paving the way for advanced time-series analysis and forecasting.
Performance review
Let’s now put the Preprocessor to the test. Don’t forget that all the aforementioned features are executed with Polars. So let’s see how it copes with a challenging task compared to the most widely used library for data handling: pandas.
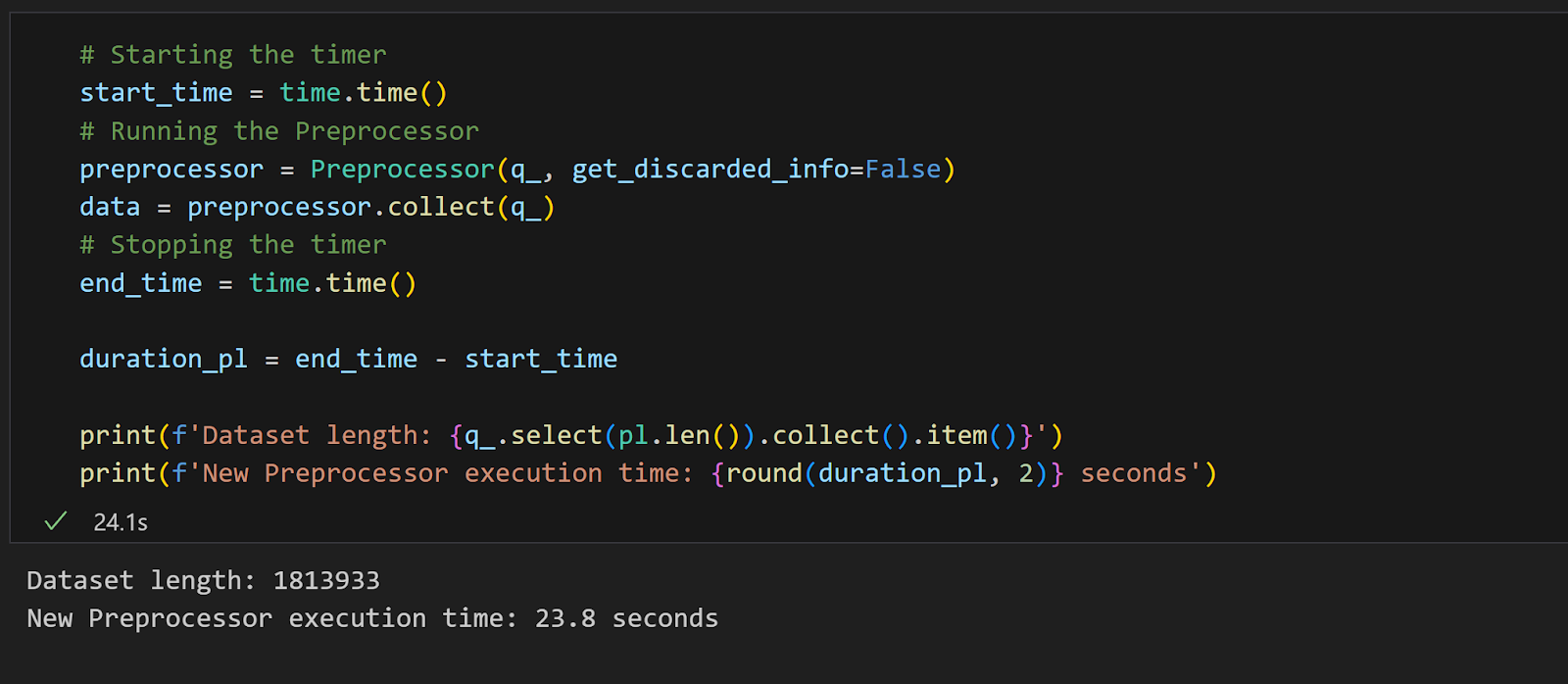
We tested the new version of the Preprocessor on a client’s dataset with 1813933 entries, on which the old Preprocessor, relying on Pandas, was struggling, returning an error for memory overload.
The new Preprocessor did not disappoint. Not only did it not crush unlike its predecessor, but it also delivered the result in just 23.8 seconds!
To be able to test the two Preprocessor versions we chose a smaller dataset. We then run the two Preprocessors 10 times, the old one on a pandas DataFrame version of the dataset and the new one on a Polars LazyFrame version of the same dataset.
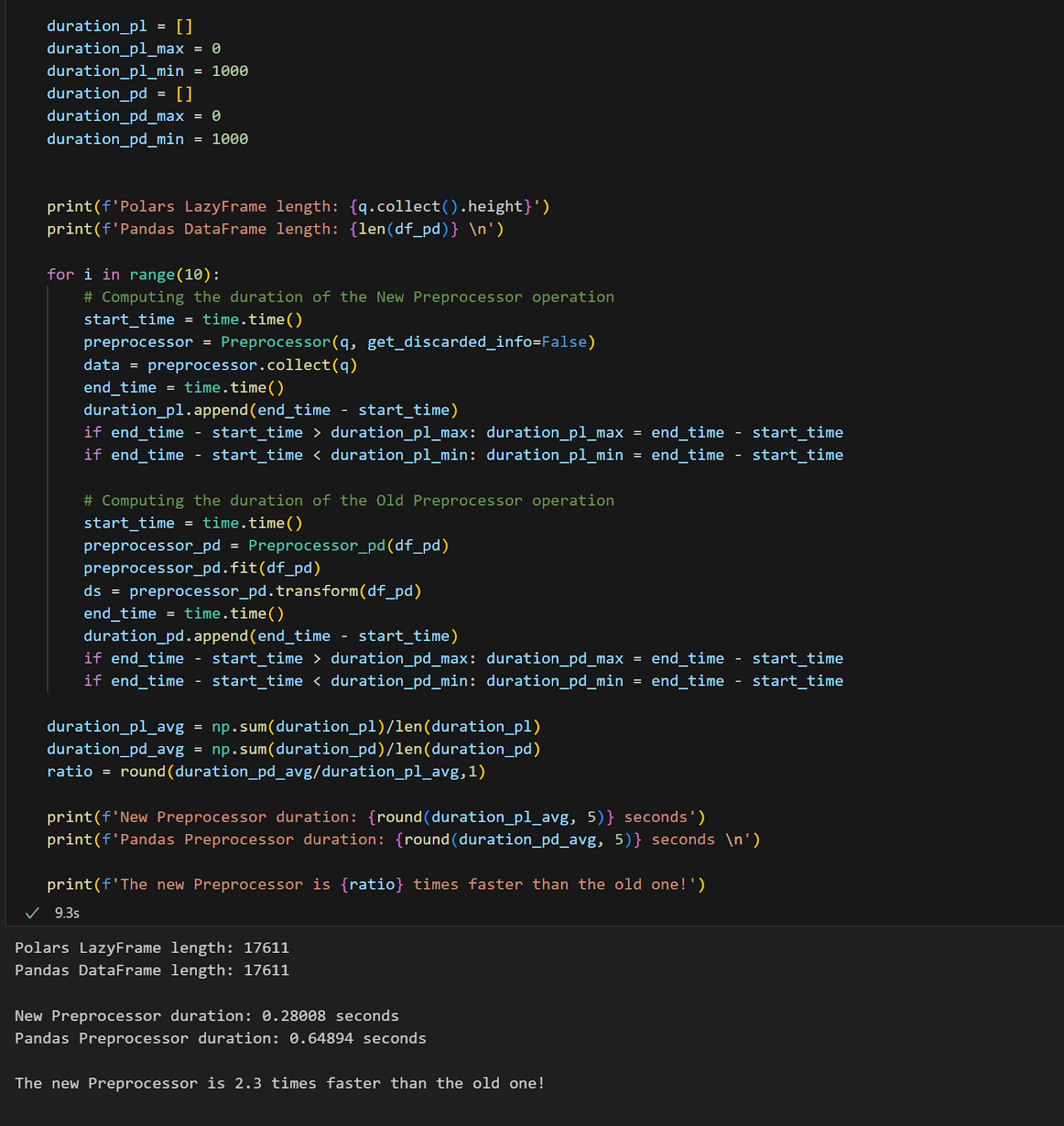
On average, the new Preprocessor was 2.3 times faster than the old one!
This is a great result, also considering that the Preprocessor 2.0 also performs new operations on the dataset that were not carried out in the previous one. So now it fulfils a greater number of operations… in less time!
Conclusion
The advantages deriving from the introduction of Polars in the Preprocessor 2.0 are clear. The new Preprocessor is more scalable, with the capability of handling larger datasets than its pandas predecessor. Besides, it reaches lightning fast performance in manipulating datasets, cutting preprocessing times by more than half, without considering the new features, like the introduction of time-series manipulation and more.
Try our new Preprocessor 2.0 to boost your data preparation now, and leave a star if you liked it!
Tags:
blogpost Dario Brunelli is a Machine Learning Engineer at Clearbox AI with a double Master’s degree and a strong background in Quantum Machine Learning and electrical engineering. He works on synthetic data projects, contributing to the development of Clearbox AI’s libraries.
Dario Brunelli is a Machine Learning Engineer at Clearbox AI with a double Master’s degree and a strong background in Quantum Machine Learning and electrical engineering. He works on synthetic data projects, contributing to the development of Clearbox AI’s libraries.