
Machine learning models learn from data. As the amount of good quality data available increases, so does the quality of the models. With more data, a model has more to learn from in order to increase its generalisation capability.
Data scarcity is one of the major bottlenecks for Machine Learning to reach production readiness. Too often, as data scientists, we focus on improving model performance. With little data available, no matter how hard we try different model architectures and training strategies, the final results will always not be optimal.
So what can you do if you’re working with tabular data and need more data to enhance your model performances? This is trivial. Here are the steps to follow: take the original dataset, Ctrl+C, Ctrl+V, slightly change some of the values and voilà, data scarcity is no more a problem. You’re welcome.

Clearly, it’s not just a matter of quantity. Data quality matters as well. Garbage in, garbage out, right? But how is the quality of an augmented dataset measured? In a nutshell, the generated data should preserve the statistical properties and distributions of an original dataset, thus resulting in a realistic cloned dataset.
If you generate synthetic data with a procedure that does not correctly capture the distributional properties for the well-known UCI Adult dataset you may get this particular instance among your new data:

Wow, it looks like this 12-year-old boy is doing pretty well with his farm. He has a PhD and works 87 hours a week, so he deserves what he gets. This intense workload probably led to his divorce. Wait, what?
This synthetic data is clearly useless. We augmented the original dataset with statistical noise that will not bring us any advantage in terms of increasing the performance of a model trained on it. By the way, how do we evaluate whether our model has improved after generating a synthetic dataset?
Evaluation of the synthetic data quality
Let’s suppose you have a dataset already split into a training set and validation set. You train a model on the training set and evaluate it on the validation set. The metrics obtained on the validation set are not too satisfying, the accuracy is rather low. Sounds like an ideal situation to generate some synthetic data, doesn't it? Your synthesizer shoots out a bunch of new instances, you add them to the original training set and re-train the model. It's time to check the metrics again. But on which data? Do you create a new validation set from the augmented dataset? No! This might intuitively seem to be the way to go, but it’s incorrect: you have to use the original validation set again! Always remember that the model will probably/hopefully be used in production on real data, not synthetic data. Evaluation must always be done on the original data. Also one would have no way of comparing with the previous metrics if they used a different validation set.
If the performance of a model has improved on the original validation set, it means that the synthesizer is of good quality, the synthetic data generated is sufficiently realistic and comparable to the original data.
AI Control Room to the rescue
Clearbox AI has developed a technology, based on generative models, that automates the generation of structured synthetic data. Synthetic datasets are obtained by generating fictitious data that incorporates the statistical properties and distributions of an original dataset.
Let's start with the familiar UCI Adult dataset. I simulated a data scarcity situation by sampling from the original dataset a training set of 500 rows and a validation set of 100 rows. We train a simple Decision Tree on this reduced training set and obtain the following metrics on the original validation set:
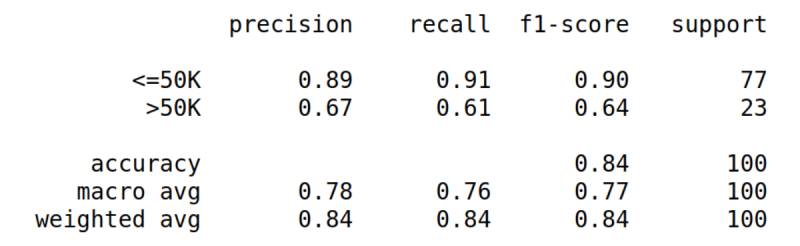
Actually, we've already obtained some pretty good metrics (thank you Scikit-learn, you're the best), but let's try to go a little further by generating 500 synthetic rows with AI Control Room, doubling the size of the original training set.
We re-train our model on the augmented dataset (original training set + synthetic data) and re-evaluate its performance on the original validation set:
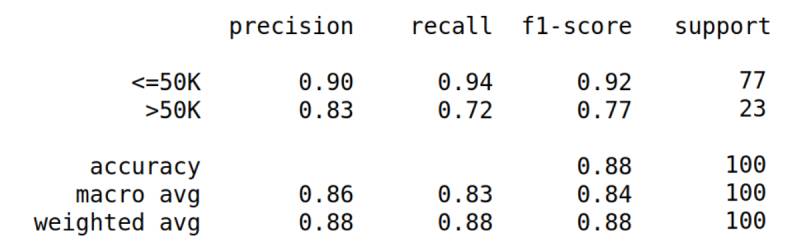
We have achieved a performance increase in accuracy on the original validation set. This means that the data generated is actually realistic and useful for improving our model, which we can now safely deploy into production! Our PM will be so happy, a big raise is coming!
If you are just as happy as our PM to read this content, stay tuned! We will publish more posts about synthetic data soon ;) in the meantime, you can discover how to evaluate the robustness of your synthetic data in one of our previous blog posts.
