
In the previous blogpost we had introduced the concept of synthetic data to the readers. Given an original dataset it is possible to generate a synthetic dataset that preserves the original statistical properties for a variety of use cases. If augmentation of data quality is the purpose, the only thing that matters is the utility or fidelity of the synthetic data with respect to the original one. But if the goal is to facilitate privacy sensitive data sharing, we need to consider all the relevant aspects around data protection. We would like to have synthetic data that is statistically very similar but at the same time, individual record wise, very different from the original data. Wait, what? Yes you read that right, it could actually solve the massive utility vs privacy conundrum.
Synthetic data, if generated correctly, protects against privacy risks. To prove this, we need metrics that help us to quantify and manage these risks.
This is the introductory post of a series about the analysis of privacy risks with synthetic data from an engineering point of view. Next time onwards, we'll get our hands dirty and go straight to the methods that we can implement. We will try to understand what it means to protect privacy with synthetic data and go into the details of some metrics useful to assess risks.
When does it makes sense to talk about data privacy
According to GDPR and related regulations, the scope of privacy measures are directed at personal data, i.e., information that pertains to living individuals also known as natural persons. This may sound trivial, but it is good to clarify. If the original dataset does not contain direct or indirect personal data about individuals, there is no privacy risk. Otherwise data privacy regulations apply.
There are several technical, organisational and policy measures to be adopted to avoid disclosure of personal data. In this post we discuss the technical measures in terms of anonymization or pseudonymization techniques, beyond the obvious cyber security measures that one needs to consider for privacy preservation.
Of course, data anonymization techniques have been available for decades, long before the rise of synthetic data generation. The risks we describe here apply to more traditional protection techniques as well. With those techniques there’s always a huge trade-off between privacy and data utility. Synthetic data generation can better deal with this trade-off: synthetic data, if done properly, is private, realistic and retains the original statistical properties. Assessing the privacy risks can help make the synthetic generation solution even more complete.
This is the starting scenario on which we will proceed for our analysis: we have an original tabular dataset O containing sensitive data about individuals. We train a generative model that gives us a synthetic dataset S with a certain degree of guarantees in terms of de-identification. A hypothetical attacker (or adversary) A tries to derive some sensitive information from S. We want to measure the privacy risks, we need practical metrics that we can calculate.
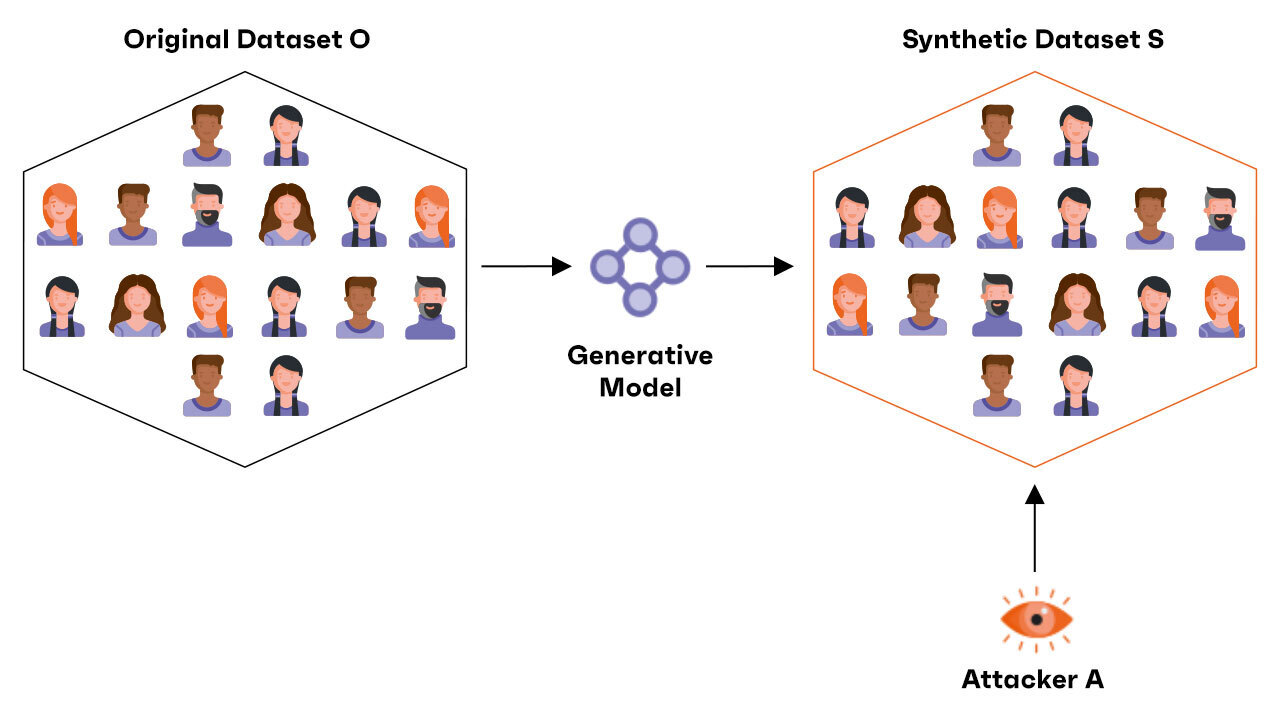
As we move forward in the analysis we will modify these assumptions slightly, but it is good to have a common reference framework right from the start.
How do we identify and manage privacy risks?
With a good synthetic data generation, where new data records are generated from a distribution learnt by a (ML) model, there is by construction no unique mapping between the synthetic records and the original ones. This is true in general, but we should not underestimate the risks. In some cases, for example, the generative model may overfit on the original data and produce synthetic instances too close to the real data. And even in the case of synthetic data that seems anonymous, sophisticated attacks could still lead to re-identification of individuals in the original dataset.
Identity disclosure
Let’s say s is a record in our private synthetic dataset S. If an attacker is able, with or without any background knowledge, to assign a real identity to that record, we call this an identity disclosure.
Only correct identity assignments matter. If the attacker assigns a wrong identity to a synthetic record or assigns an identity of a real person who was not present in the original training dataset, there is no identity disclosure.
Assessing the risk and relevance of an identity disclosure, we must take into account the background knowledge and resulting information gain of the attacker. Did the attacker learn something new about the identified subject? If it is able to assign a real identity to a synthetic record, but it already knew all the attributes of that individual, it did not learn anything new from this assignment, the information gain is zero. We should be particularly concerned only with the risks derived from identity disclosures where the information gain is greater than zero.
A good synthetic data generation protects from these meaningful identity disclosures.
Inferential disclosure
Direct identity disclosure is highly unlikely by construction with fully synthetic data but an attacker could use data analysis to derive information about a particular group of individuals without assigning an identity to a specific synthetic record. Let’s say the original dataset contains sensitive medical information. The generated synthetic dataset preserves the original statistical properties. Given the synthetic dataset the attacker could derive that a certain group of people with similar characteristics have a certain risk of contracting a disease. This could be done with basic statistical techniques or in a more sophisticated way with a machine learning model. At that point, if it knows another individual (who may not even be part of the original dataset) who has the same characteristics as that group, it can derive that that person has the same risk of contracting the disease. The adversary learnt something new about an individual without any actual identity disclosure. This is called inferential disclosure.
This is not a disclosure from which synthetic data can protect us and for this very reason we should be aware of it and quantify it to make decisions on the proportionality principles. Let me explain in more detail.
Deriving inferences from data is the essence of statistics and data analysis. A dataset is useful only if it is possible to identify some relationship or pattern within it and derive additional information, otherwise it’s just noise. Synthetic data with a high utility will retain the original relationships in the data. Therefore no matter the level of synthetic data privacy, if they preserve the statistical properties of the original ones, you should be aware that potentially someone can learn something new about (a group of) individuals from them. This can be harmful to those individuals, but this holds for any kind of information derived from data. Data synthesis cannot help here, these kinds of concerns have to be handled in other ways.
Membership Inference Attacks
Membership Inference attacks try to infer membership of an individual in the original dataset from which the synthetic dataset was generated. For example, if the original dataset used to train the generative model consists of records of people with cancer (the cancer status is not a column of the dataset, but it’s shared as a clinical study of cancer patients), being able to infer from the synthetic data that an individual was included in the training set will reveal that that individual has cancer.
As in the case of inferential disclosure, with MIAs an adversary could learn something new about an individual without an actual identity disclosure but the focus here is about the membership of a known individual (background knowledge) to the original training set.
This is not an exhaustive list of all possible risks related to privacy preservation of synthetic data, but it should give a clear idea of the issue. We like to be thorough about all the possible risks but we need to be aware that risk and remedy when it comes to data protection is based on the proportionality of the risk and impact. In anycase synthetic data is a great contender as a safeguard mechanism in managing risks.
Stay tuned for the next post of the series, we’re going in more detail and start implementing some methods to assess the risks in practice.
