
Article wrote in collaboration with Shalini Kurapati. Dr. Luca Gilli is the CTO of Clearbox AI, Dr. Shalini Kurapati is the CEO of Clearbox AI and is a Certified Information Privacy Professional, Europe (CIPP/E).
In the last few months we extensively worked with generative models, to perform uncertainty analysis and to apply perturbation based interpretability techniques. We recently had an interesting exchange with a practitioner who asked whether the same generative model could be used to ‘clone’ a dataset. By cloning a dataset one generates a proxy dataset representing the same information of the original one purely with synthetic data. This can be an effective privacy preserving technique when we have to build a model on a sensitive dataset which cannot be shared by a client due to privacy concerns.
While creating a proxy dataset is not a new concept, we wanted to test whether we could clone a dataset with precision using our generative model technique.
Let’s consider a toy dataset, the adult income census which is a classic binary classification use case. We used this data to train a Conditional Variational AutoEncoder (CVAE) on the remaining data. A CVAE learns to generate new data based on the conditional distribution P(X|z,y) where z is a latent variable distributed according to a simpler probability distribution, for example a normal distribution, and y is the label for which we want to generate data. Once the conditional CVAE was trained on the census dataset we recreated a synthetic dataset by sampling z,y (according respectively to the distribution learnt by the encoder side of the CVAE and to the label distribution in the original dataset).
The following figure shows a comparison of the distributions of 4 columns of the synthetic dataset with respect to the original one:
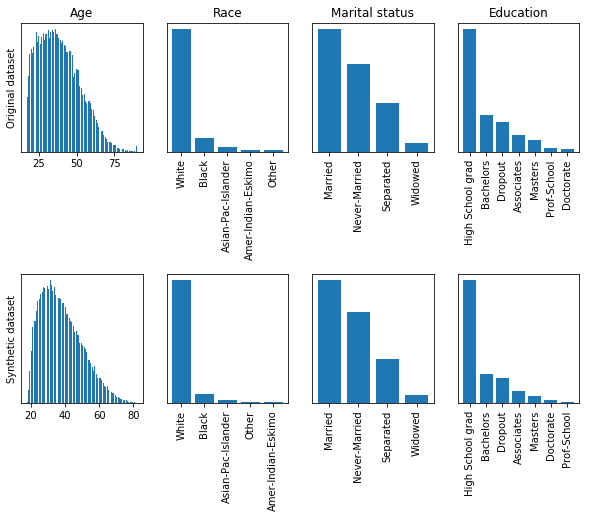
The top and bottom distributions look indeed similar, the CVAE seems to be able to reconstruct the original information properly. It is interesting to notice how the age distribution slightly differs on the lower end of the curve. The reason is that the dataset only contains individuals from the age of 18 onwards so there is a sudden cut in the probability density function of the variable. The CVAE was not able to properly model this behaviour because of the assumption that the generative variable z is normally distributed which in fact introduces a limitation in the generative process.
After generating the synthetic dataset we trained two classifiers, one using the original the other using the cloned one. The classifier model was for both dataset a random forest. The two classifiers have been finally tested on the hold-out dataset which was initially set aside before training the CVAE.
- Test accuracy classifier trained on original data: 83.0%
- Test accuracy classifier trained on synthetic data: 82.5%
The figure below shows the precision-recall curves for both classifiers:
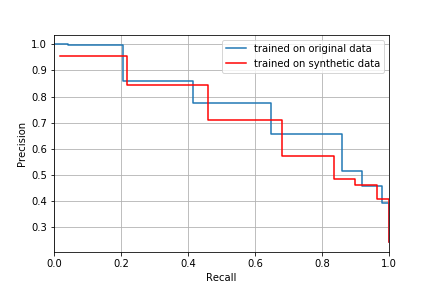
The overall performance of the classifier trained on synthetic data is comparable to the one trained with the original data which is a promising result.
Balancing accuracy and preserving privacy is a tight balancing act. We all know the struggles of accessing sensitive data to build and train an AI model. In this context data cloning is definitely a viable alternative to avoid privacy headaches, while we can train the model at good performance levels with the proxy dataset. Data cloning cannot be considered as a full anonymisation tecnique since it can still be prone to inference breaches, since by now, we know that it is almost impossible to make any dataset fully anonymous. In this light, the cloned datasets are not to be shared openly without the appropriate safeguards and agreements between parties. Nevertheless it is a facilitating step forward in ‘accessing’ sensitive data to build trust and trustworthy AI models that will also work on the real datasets in production. We should consider data cloning as a risk mitigation technique like anonymisation, pseudonymisation, scrambling etc. whose use is encouraged by leading privacy laws like the GDPR.
Tags:
blogpost Dr. Luca Gilli is the CTO and the chief scientist at Clearbox AI. He is the inventor of Clearbox AI’s core technology and leads the R&D and product development at the company.
Dr. Luca Gilli is the CTO and the chief scientist at Clearbox AI. He is the inventor of Clearbox AI’s core technology and leads the R&D and product development at the company.